§ 02 · RESEARCH
Research.
INDEX
[ 08 of 08 · 4 years ]
ALL [8]
PUBLICATIONS [5]
PROJECTS [3]
KIND
ALL TOPICS [8]
MUSIC [4]
NLP [2]
AUDIO [2]
TOPIC · SORT DATE DESC
2025
2 entries2025.04
NAACL
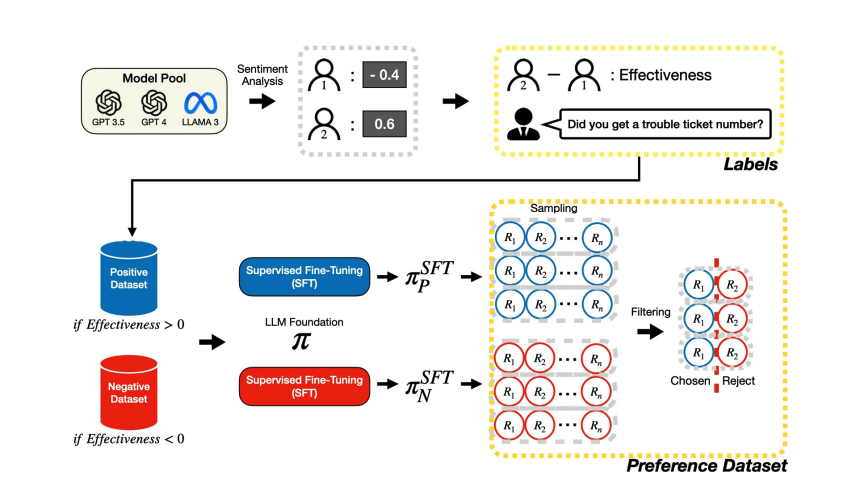
Sentimatic: Sentiment-guided Automatic Generation of Preference Datasets for Customer Support Dialogue System
SuHyun Lee, ChangHeon Han · NAACL 2025
Automatic, sentiment-guided framework that produces large-scale preference datasets without human annotation — improves emotional appropriateness in customer-support LLMs.
Dialogue Systems
Preference Data
NLP
2025.07
ACL-W
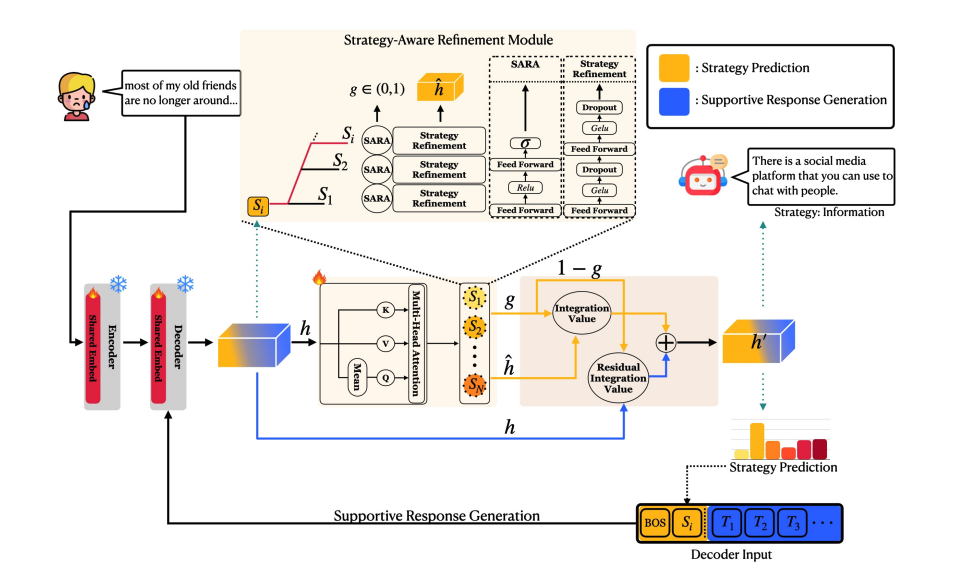
STAR: Strategy-Aware Refinement Module in Multitask Learning for Emotional Support Conversations
SuHyun Lee, ChangHeon Han, Woohwan Jung, Minsam Ko · ACL 2025 (NLP4PI Workshop)
Disentangles decoder representations and dynamically fuses task-specific info — state-of-the-art in both strategy prediction and response generation.
Emotional Support
Multitask Learning
NLP
2024
2 entries2024.06
ICASSPW
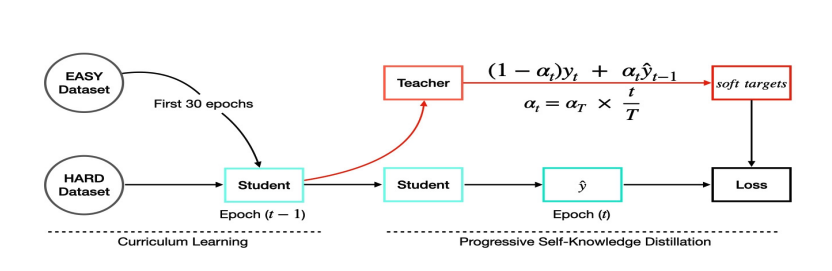
Optimizing Music Source Separation in Complex Audio Environments Through Progressive Self-Knowledge Distillation
ChangHeon Han, SuHyun Lee · ICASSP 2024 Workshops
Fine-tuning strategy for hearing-aid–oriented source separation. Softening targets with previous-epoch predictions gives +1.2 dB SDR over the baseline.
Music Source Separation
Knowledge Distillation
Audio
2024.06
KCC
ASMR Sound Generation through Attribute-based Prompt Augmentation
ChangHeon Han, Jaemyung Shin, Minsam Ko · KCC 2024
LLM-based prompt augmentation that explicitly models ASMR triggers — produces more detailed sound descriptions and improves T2A quality.
Text-to-Audio
Prompt Augmentation
ASMR
NO COVER
2023
3 entries2023.11
ISMIR
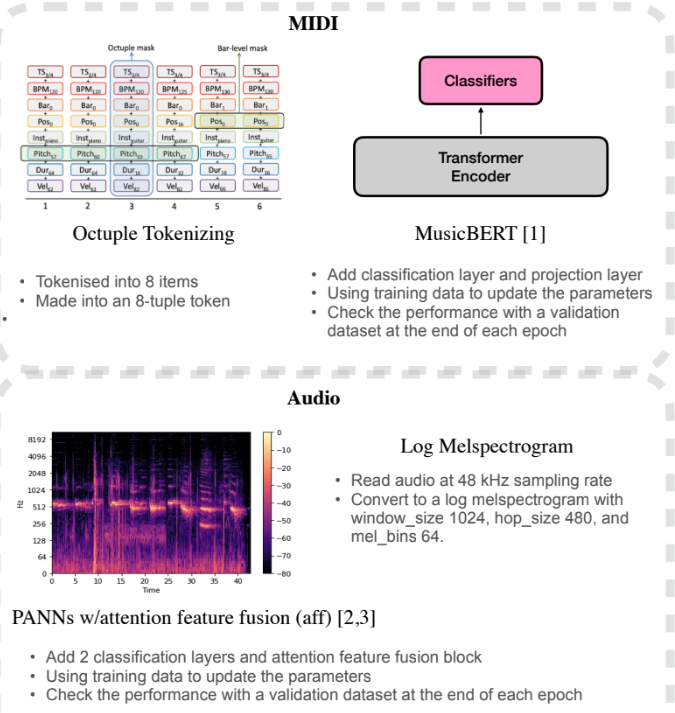
Track Role Prediction of Single-Instrumental Sequences
ChangHeon Han, SuHyun Lee, Minsam Ko · ISMIR 2023 LBD
Predicts the track role of single-instrument sequences automatically. 87% symbolic / 84% audio accuracy — reduces manual annotation in MIR pipelines.
Music Information Retrieval
Sequence Modeling
2023.01
TOOL
// PROJECT
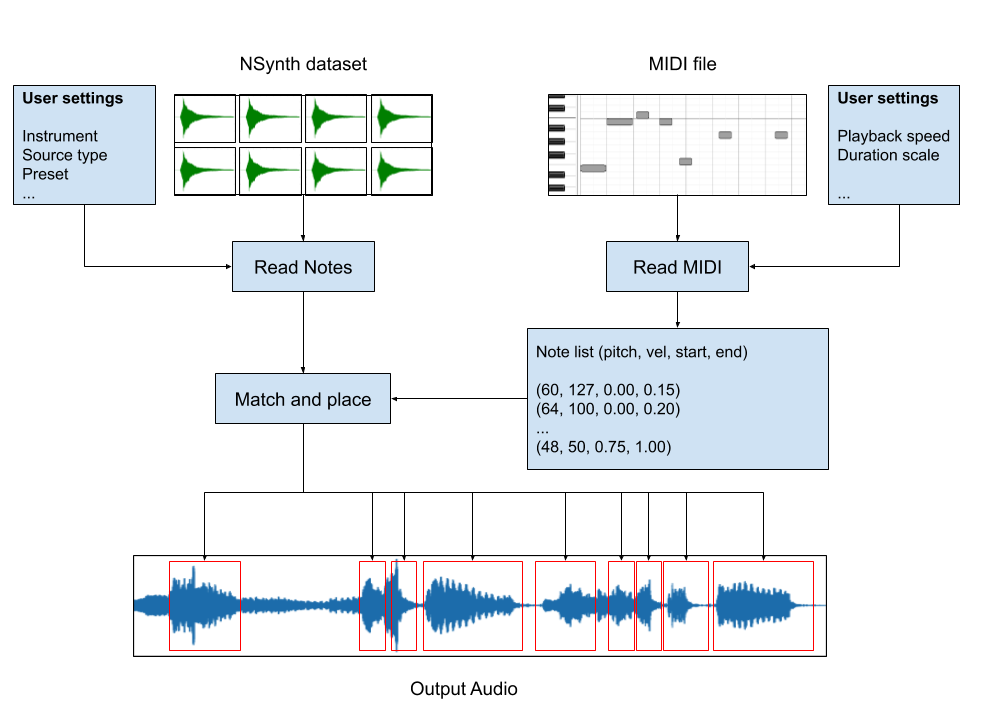
NSynth-MIDI-Renderer for massive MIDI dataset
ChangHeon Han · Open-source tool
Open-source renderer that picks NSynth candidates and locks a single preset across a MIDI sequence — used to synthesize massive symbolic-to-audio datasets.
Music Information Retrieval
MIDI
Dataset
2023.01
TOOL
// PROJECT
MIDI-Metadata-Extractor
ChangHeon Han · Open-source tool
Segregates a multi-track MIDI file into individual instrument tracks, extracts per-track metadata, and supports measure-based truncation / save.
Music Information Retrieval
MIDI
NO COVER
2022
1 entries2022.01
TOOL
// PROJECT
Soothing Sound White Noise Generator
ChangHeon Han · Project · KCC copyright
Soothing-sound audio generator with five distinct noise colors and three weighting filters. Copyrighted with the Korea Copyright Commission.
Audio
Signal Processing
NO COVER
© 2026 · CHANGHEON HAN · BUILT IN GOTHENBURG